ZooKeeper
ZooKeeper是大家最熟悉的开源的分布式协调服务,提供了高可用、高性能、稳定的分布式数据一致性解决方案.
单一系统映像
绝大部分介绍ZooKeeper的博客在说到其特点和功能时总是会说
单一系统映像:无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
实际上这句话确实来自于ZooKeeper官方的文档说明,原文为
Single System Image:A client will see the same view of the service regardless of the server that it connects to.
误解
事实上这句话并不能说错,但是确实具有不准确的误导性.
很多人会认为这句话的含义是: 当客户端A将资源R的值进行了修改,R1->R2->R3的情况下,客户端B只要请求是在A客户端收到R值修改成功的响应后到达的ZooKeeper服务器,那么客户端B看到的R值必然是R3.
这是一种错误的理解,事实上客户端A和B并不能保证无论如何都看到相同的R值即R3.
也就是说单一系统映像机制并不能保证读操作的严格数据一致性.
对这个问题其实有一个stackoverflow的问题,同时对于这个问题也有对应的修改该特点说明的pull请求.
如果有兴趣的话可以去看看这个issue的说明,里面明确表达了上面的这种理解确实是错的,并且最后开发人员接受了这个pull请求.
里面的issue提出者和开发者的话是这样的
Because the old one is a little misleading, if cluster has a outdated follower and a normal follower, I do not think a client will see the same view of the service regardless of the server that it connects to at its first connection.
Yep,the description is a little misleading.IMO,What the “Single System Image” means is that a client cannot read the stale data that it had ever read regardless of the server that it connects to. e.g: set /key v1–>v2–>v3 A client’s view of the /key cannot be like: v1–>v3–>v2.
在原来的Single System Image后面追加了说明内容
A client will see the same view of the service regardless of the server that it connects to. i.e., a client will never see an older view of the system even if the client fails over to a different server with the same session
也就是说单一系统映像的真正含义是对于某客户端来说看到过新版本的值后,无论如何也不可能会再看到旧版本的值.只能看到该新版本的值或者更新版本的值.
依旧以上面的情况举例:客户端A将资源R的值进行了修改,R1->R2->R3,客户端B去查看资源R的值
在这种情况下,客户端B看到的资源R的值可能是从R1开始的任何值.
但是如果我们假设客户端B第一次看见的资源R值为R2,无论什么情况下,ZooKeeper都保证客户端B不可能再看见R1.
也就是说保证的是客户端级别的单调递增一致性.
机制
首先我们来看ZooKeeper的架构图
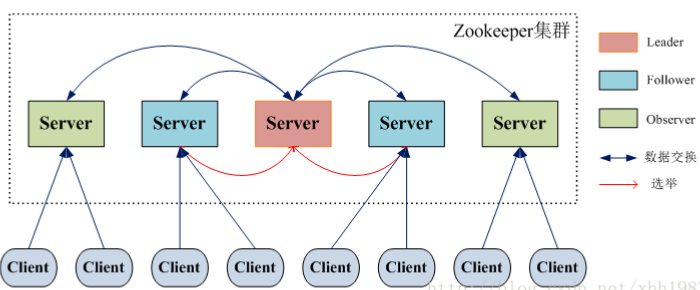
我们来整理一下,ZooKeeper具有如下的机制:
- ZooKeeper服务器与客户端的之间通过一个TCP长连接交互,在一个session期间,同一个客户端交互的服务器节点固定.
- Leader是集群中唯一的写请求处理者,能够发起投票(投票也是为了进行写请求).
- Follower能够接收客户端的请求,如果是读请求则可以自己处理,如果是写请求则要转发给Leader.在选举过程中会参与投票,有选举权和被选举权.
- 写操作请求时过半Follower写成功即为该写请求成功
- ZooKeeper集群只有在更换master,选举新master并进行同步状态的期间会不可用
- 客户端和服务端都会保存自己当前的最新事务id即zxid.客户端连接到服务器时,当其当前zxid小于客户端的lastZxid时,该服务器将拒绝连接.
流程
那么根据如上的机制,我们可以整理出客户端使用ZooKeeper写资源的流程如下:
- 客户端发起对资源的写操作请求
- 与该客户端保持session的ZooKeeper服务器接收到写操作请求
- 如果该ZooKeeper服务器的身份是Follower或者Observer则将写操作请求转发给Leader
- ZooKeeper的Leader服务器接收到写操作请求,生成递增事务id,即zxid
- ZooKeeper的Leader服务器使用步骤4生成的zxid向所有Follower发送proposal请求,要求Follower执行该写操作
- ZooKeeper的各个Follower服务器比较接收到的zxid和本机保存的zxid,如果本机zxid小于收到的zxid,则把proposal保存到本地日志事务中,然后返回proposal ack响应,表示已经执行该写操作
- ZooKeeper的Leader服务器收到过半的proposal ack响应结果后,认为该写操作已经成功.向客户端返回成功响应,并向所有Follower发送commit请求,要求Follower提交该写操作的事务,同时向所有observer发送写操作请求.
- ZooKeeper的各个Follower服务器收到commit请求后,就正式提交该写操作的事务,然后返回commit ack响应,表示已经提交该写操作的事务.各个observer服务器收到写操作请求后,完成后也返回ack响应.
从上面的流程可以看出,其实到了步骤7的时候客户端就已经收到了写操作的成功响应,代表ZooKeeper承诺写操作已经生效,不会被丢弃.也已经可见了.
而客户端读资源的流程则很简单,ZooKeeper服务器直接返回内存中该资源的值给客户端.
那么我们现在假设客户端A对于资源R的写操作R1->R2已经成功,收到了成功响应. 而客户端B连接的是一个Follower服务器而且这个Follower服务器由于网络阻塞或者网络波动,并没有收到R1->R2的写操作请求,此时客户端B请求读取R资源的值,自然就会读取到R1而不是R2.
保证读写全局单调递增一致性的代价
如果希望做到避免这样的情况,那么我们需要如何修改流程呢?
那就是在上面的步骤7时并不返回客户端成功响应,而是等到步骤8中的所有Follower和observer服务器都返回了commit ack响应才返回写入成功.
代价就是极大地增加响应时间,并且如果有某个节点不可用,那么整个集群就不可用了.
或者学习raft协议把读操作的请求也作为需要排队的队列,按照顺序进行apply.代价也是增加响应的时间.
或者把写操作的成功响应和其结果的可见性承诺分离.也就是说写操作成功,不代表结果可以被读操作获取到.而是要等到所有服务端都写成功了才可见.
总结
单一系统映像机制并不能保证读操作的严格数据一致性.
单一系统映像的真正含义是保证客户端级别的单调递增一致性:对于某客户端来说看到过新版本的值后,无论如何也不可能会再看到旧版本的值.只能看到该新版本的值或者更新版本的值.