rocketmq、kafka与其他消息队列的最大不同点
ActiveMQ、RabbitMQ等以前的消息队列和rocketmq、kafka两个消息队列的最大不同点在于消息持久化层的定位.
消息队列传统架构
对于ActiveMQ、RabbitMQ等以前的消息队列来说,每一条消息都有且只有一个明确的发送方和一个明确的接收方. 即使是广播模式的消息,实际上每条消息也只有一个接收方,实际上是给每个每个接收方发送了一条相同的消息. 因此在这种架构下,可以很方便地实现对每一条消息地管理,无论是消息的顺序和优先级还是消息的当前消费状态管理都很容易就能做到. 这种设计下,消息持久化只是一个异常状况下的消息备份功能的作用,在普通的消息发送和消费流程中没有作用.
消息队列新架构
由于这种设计下消息队列的单机性能效率较低的问题. rocketmq、kafka则采用另一种思路.
既然为了备灾,所以消息持久化是不可避免的,那么直接就把消息持久层作为一个消息的中间层,一条消息并不是直接发送给接收方而是先发送到中间的消息持久层,再由接收方从中间的持久层获取消息.
转换了思路以后,由于有了中间层,所以广播模式下所有消费者可以共用一份消息,只记录消费者对消息的消费进度,一条消息不再只有一个接收方,缩减了IO操作的时间和需要的磁盘容量.加上只采用磁盘的顺序操作来极大的增加了消息队列的效率和性能.
rocketmq与kafka的功能和设计区别
功能区别
1.rocketmq支持固定等级延时消息,kafka不支持固定等级延时消息
总结来说,将延时消息首先作为普通消息以特定的主题写入持久层,然后自己内部开启消费者,对每个等级的延时消息队列对应单独一个定时任务进行轮询,将到达预定时间的消息再次发送.
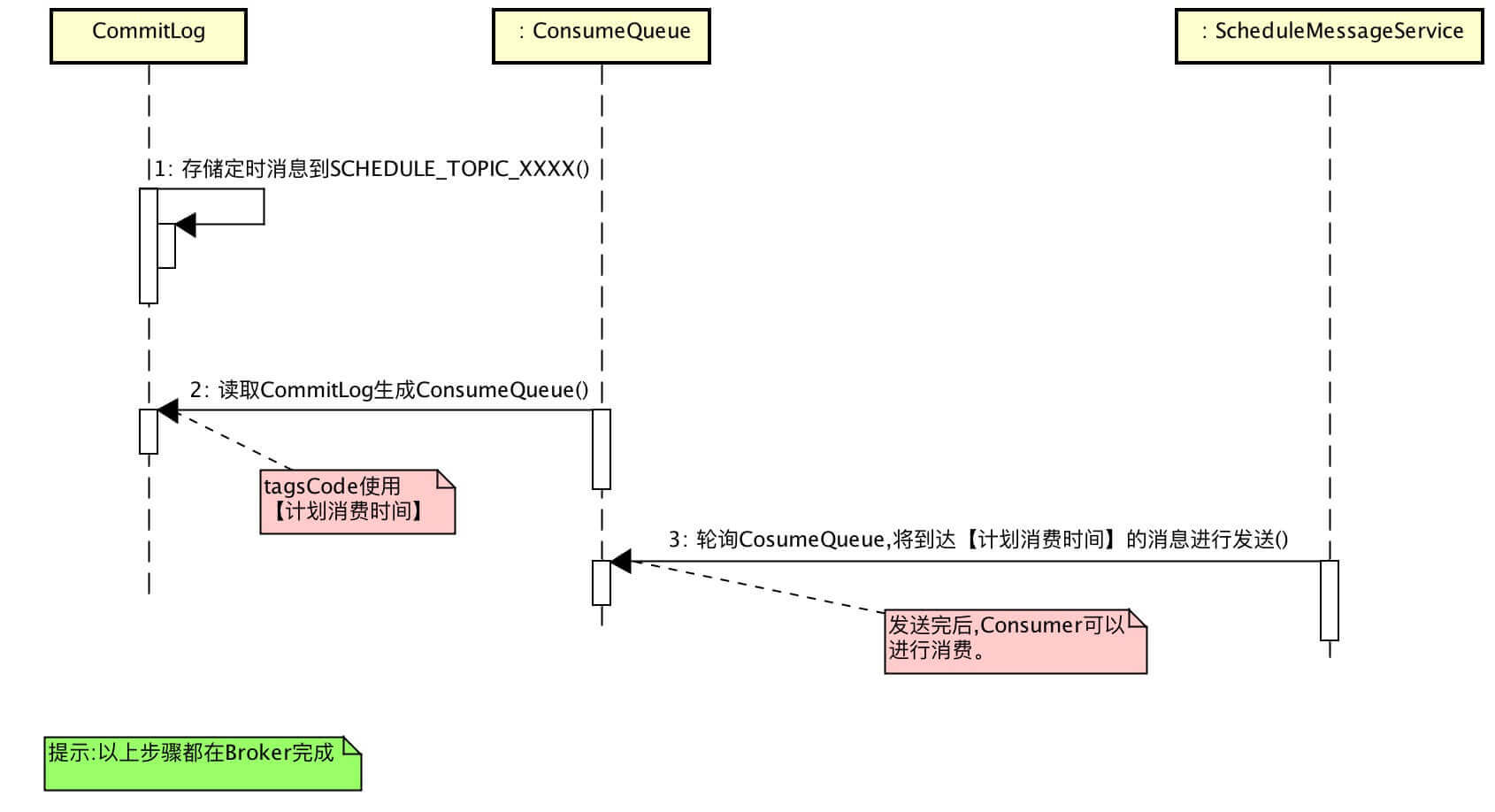
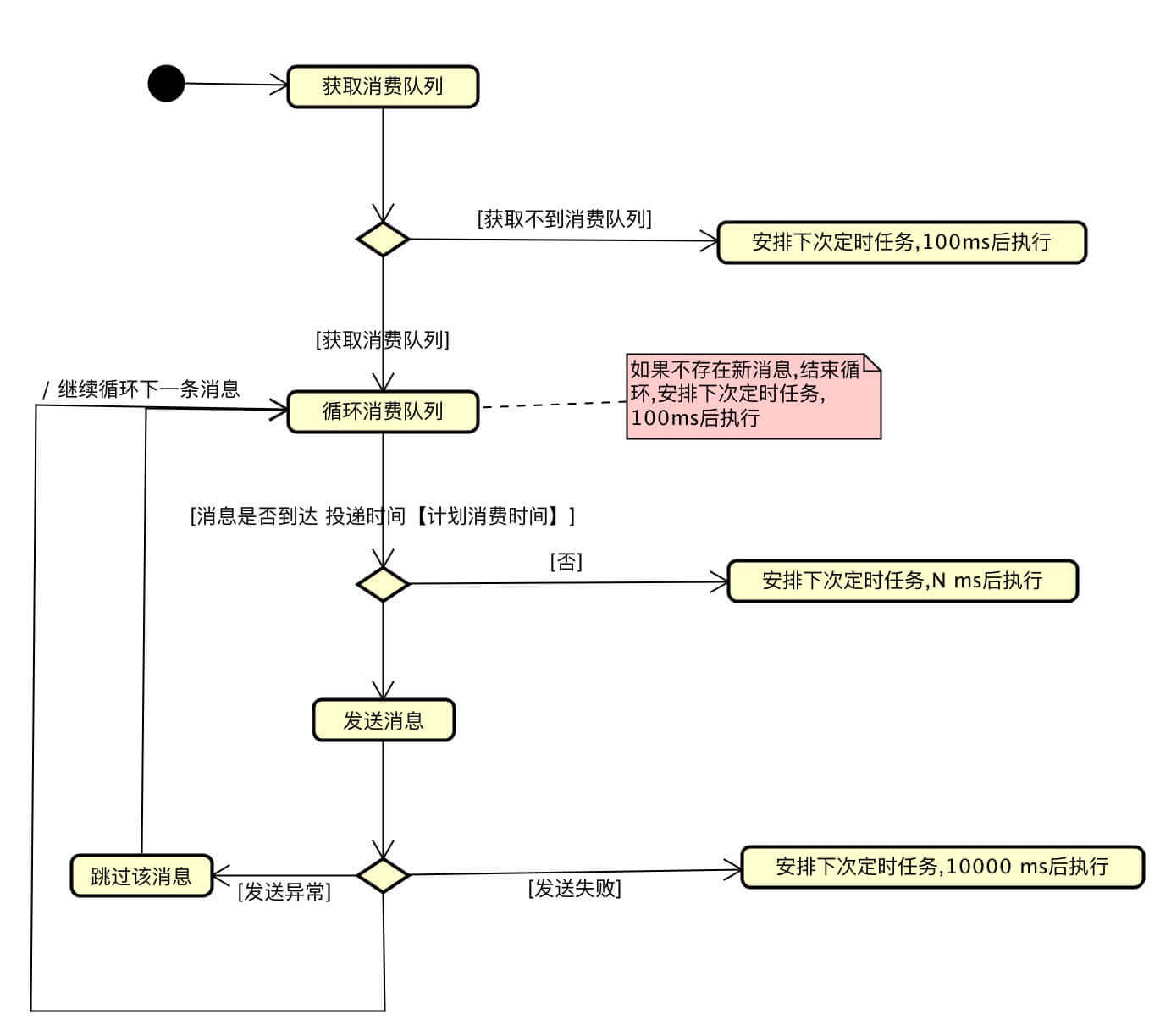 所以实际上定时消息是将一条消息发送了两次.
所以实际上定时消息是将一条消息发送了两次.
2.rocketmq支持消息重试,kafka不支持消息重试
总结来说,消息重试的本质就是再发送一条新的延时消息,并且让其他消费者过滤掉这条延时消息.
3.rocketmq支持中间层消息过滤,kafka不支持中间层消息过滤
为什么 Broker 不提供过滤消息的功能呢?我们来看看官方的说法:
Broker 端消息过滤 在 Broker 中,按照 Consumer 的要求做过滤,优点是减少了对于 Consumer 无用消息的网络传输。 缺点是增加了 Broker 的负担,实现相对复杂。
(1). 淘宝 Notify 支持多种过滤方式,包含直接按照消息类型过滤,灵活的语法表达式过滤,几乎可以满足最苛刻的过滤需求。
(2). 淘宝 RocketMQ 支持按照简单的 Message Tag 过滤,也支持按照 Message Header、body 进行过滤。
(3). CORBA Notification 规范中也支持灵活的语法表达式过滤。
Consumer 端消息过滤 这种过滤方式可由应用完全自定义实现,但是缺点是很多无用的消息要传输到 Consumer 端。
就是在这种考虑下,Filtersrv 出现了。减少了 Broker 的负担,又减少了 Consumer 接收无用的消息。当然缺点也是有的,多了一层 Filtersrv 网络开销。
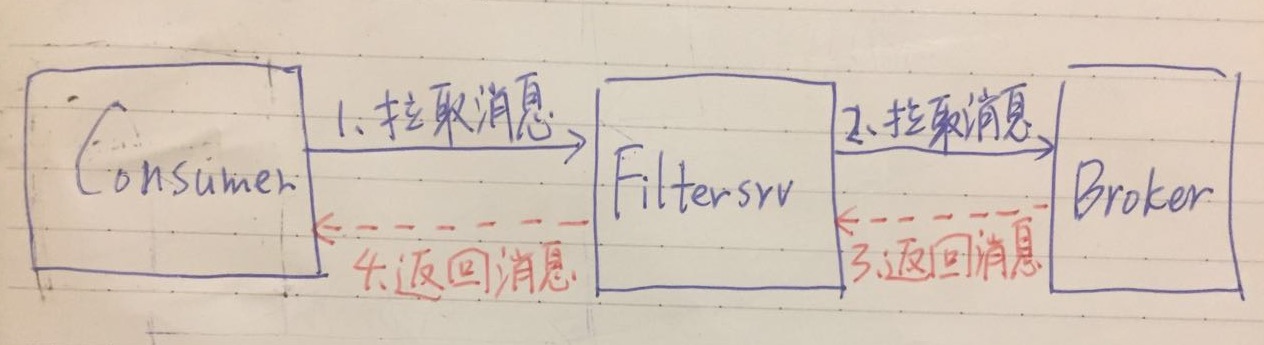
4.rocketmq不支持多种消费模式,kafka支持多种消费模式
kafka支持至少消费一次(At Least Once)、最多消费一次(At Most Once)、正好消费一次(Exactly Once)三种消费模式,而rocketmq只支持至少消费一次(At Least Once)模式. 至少消费一次(At Least Once)和最多消费一次(At Most Once)比较简单,区别只是偏移量(offset)到底是拉取消息的时候修改还是客户端提交确认信息后修改. 但是正好消费一次(Exactly Once)就比较难以实现,内部逻辑比较复杂.
架构区别
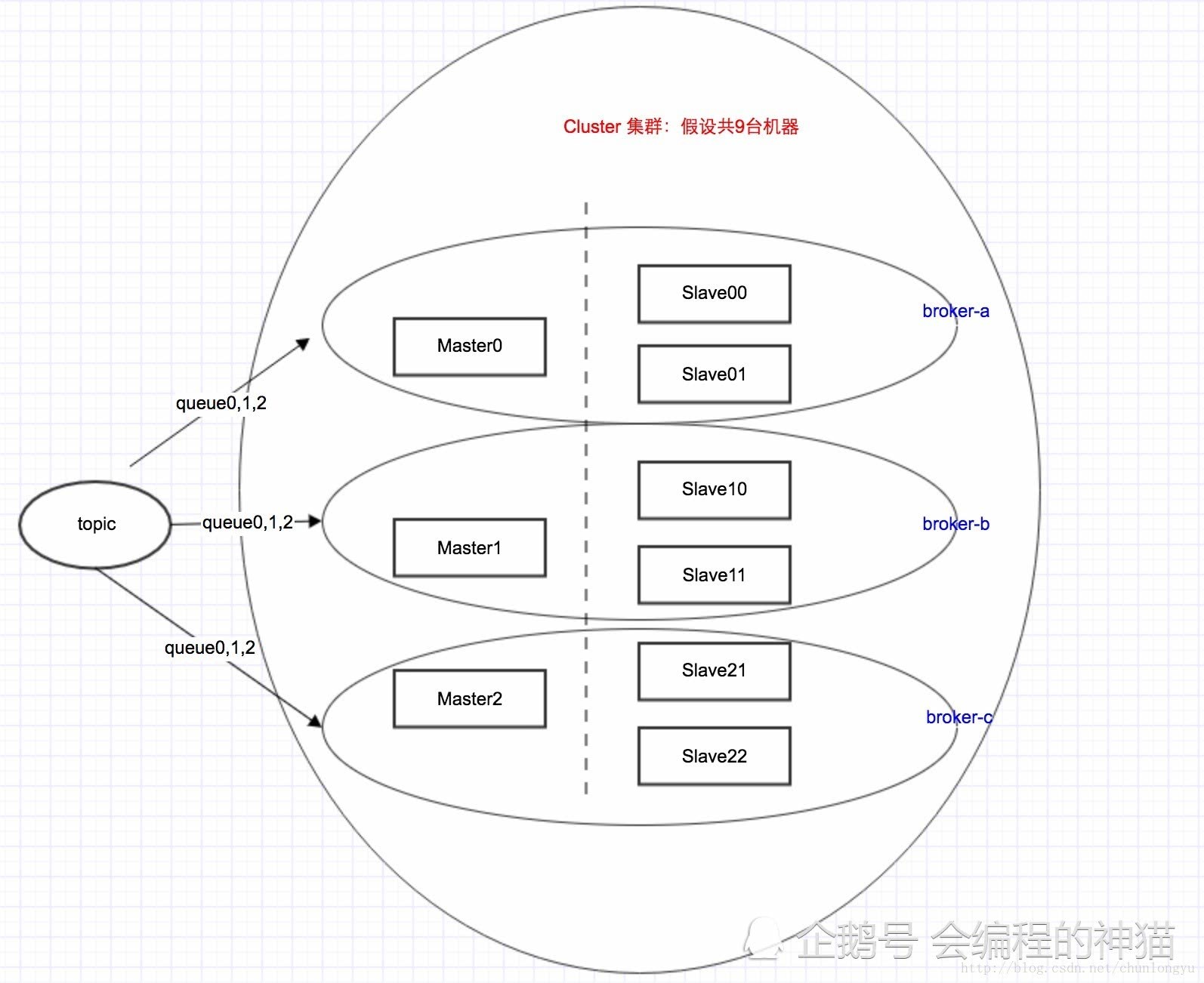
1.高可用协调节点方式的区别 rocketmq与kafka为了高可用都会将每个消息存储服务启用多个服务,多份写入,多重备份来实现高可用. 但是kafka是依赖Zookeeper的,而rocketmq去除了对Zookeeper的依赖,使用自定义的NameSrv来管理这些消息存储服务.
两者的最大区别在于管理目标: 在kafka:Master/Slave是个逻辑概念,1台机器,可以同时具有Master角色和Slave角色。且Master角色和Slave角色是动态的,如果master挂了,某个slave会升级为master对外提供服务.
RocketMQ: Master/Slave是个物理概念,1台机器,只能是Master或者Slave。在集群初始配置的时候,指定死的。如果master挂了,就会切换到另一个master,如果没有新的master,就无法写入新的消息了.
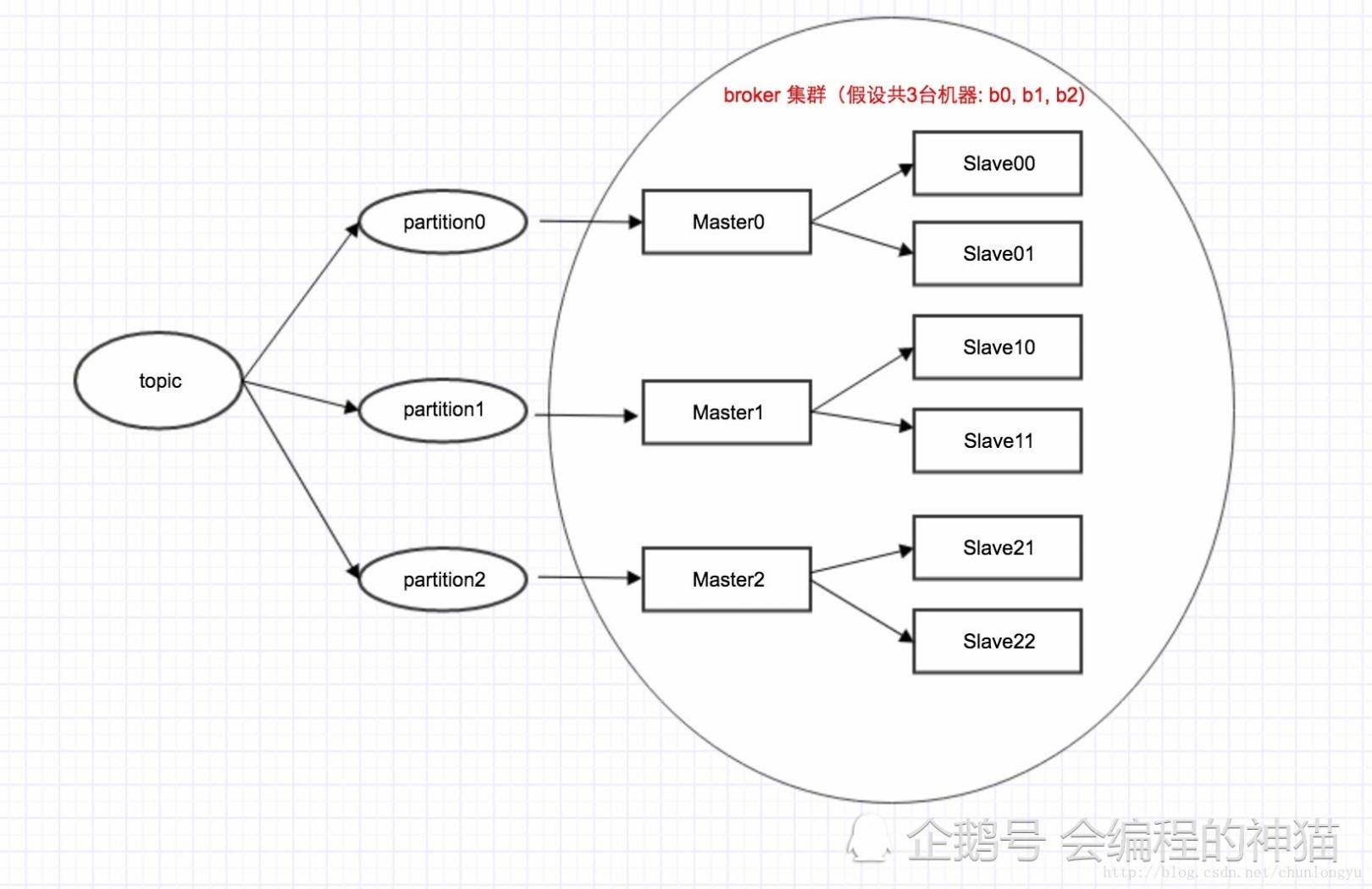
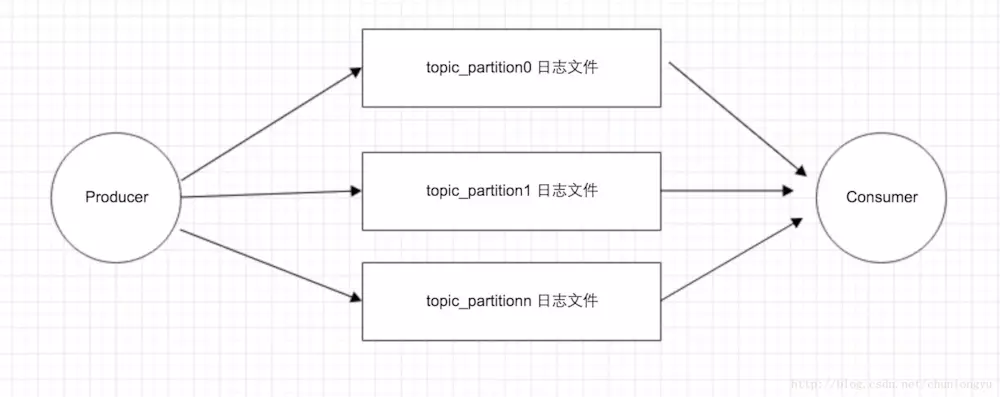
2.文件写入的区别 kafka在消息存储过程中会根据topic和partition的数量创建物理文件,也就是说我们创建一个topic并指定了3个partition,那么就会有3个物理文件目录,也就说说partition的数量和对应的物理文件是一一对应的。
RocketMQ真正存储消息的commitLog其实就只有一个物理文件。
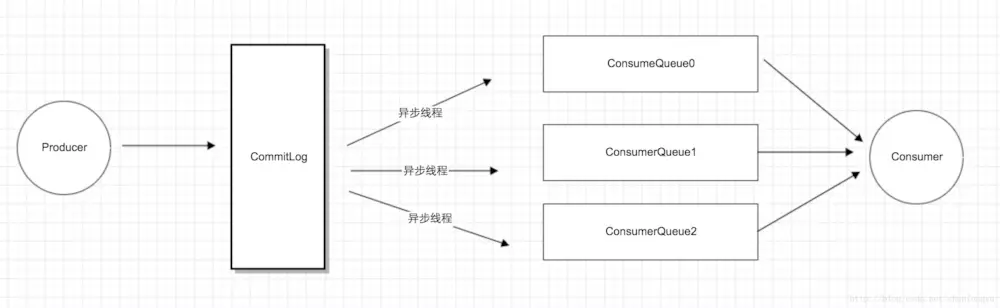
如rocketmq是长轮询,kafka是短轮询之类的区别较小,且随时可能在某个版本更新中消失,比如kafka现在也已经换成了长轮询,所以略过不提
数据平台的消息设计和原因
使用数据库为载体参考kafka和rocketmq的设计实现.
不采用包装加密rocketmq的原因:
1.上面提到了rocketmq只支持至少消费一次(At Least Once)模式,不支持最多消费一次(At Most Once)、正好消费一次(Exactly Once)模式. 由于其他公卫系统经常不提供查询接口,也不提供幂等的写入接口,所以消息消费模式上有功能性的不符合.
2.rocketmq为长连接模式,且因为是内部使用的中间件,所以安全方面需要考虑的比较多.
采用最多消费一次(At Most Once),内部设置consumeOffset和commitOffset两个偏移量,
同时设置两个偏移量的好处是,能够记录和管理没有被确认的消息.
参考列表
Kafka设计解析(八)- Exactly Once语义与事务机制原理