单例模式(Singleton Pattern)
一、设计模式(Design pattern)
一个程序员应该不会对设计模式这个词感到陌生.
设计模式其实就是有经验的程序员在软件开发过程中面临的一般问题的解决方案的归纳和总结,能被归纳总结后留下来的,自然是被认为比较好的解决方案.
从某种意义上来说,设计模式其实说明了语言的不足和缺陷,语言没能够把这些抽象集成到语言中.
理想的语言应该是不需要任何设计模式的.
比如四人帮的《设计模式》中的23个设计模式有很多设计模式就纯粹是为了弥补静态语言的”缺陷”用的(动态语言为了弥补缺陷付出的代价也不小,只是设计的取舍,不能说是真正的缺陷,所以加引号).
因为动态语言的特性,原来的所谓设计原则,在动态语言中并不需要特别的设计:
开闭原则:动态语言天生就是对扩展和修改都开放的,不需要任何特别的设计。只要一个新的对象有以前对象相同的属性,它就可以替代以前的对象;只要一个新的callable接受相同的参数,它就可以替代以前的callable。甚至,在必要的时候,以前的实现也可以通过修改类来完全替换掉(Python中一般叫monkey patch)。
里氏代换原则:动态语言中只需要考虑Duck Type,Duck Type都可以互相替代,子类天生是Duck Type,仅此而已。
依赖倒转原则:这个仍然是很重要的,但是在动态语言中,可以认为上层用到了哪些特性,哪些特性就是接口,不需要特意定义。这样不管是增加还是减少都比较容易。要让这个依赖的部分最小化,仍然需要精心设计。
接口隔离原则:同上,用到的才是接口,没有用到的就等于不存在,可以不用实现,可以认为接口天生是最小化的。还可以通过动态检测判断输入是否实现了某个接口,从而自动适应不同特性。
最少知道原则:这个仍然需要设计保证。
合成复用原则:在动态语言中,合成与继承没有本质的区别,无论使用哪一种都不会造成问题。合成可以通过动态属性或者直接复制属性来假装自己是继承关系,继承也可以通过动态属性屏蔽来自父类的接口(比如在Python中可以raise AttributeError)来假装自己不是父类的派生类,甚至还可以不调用父类的__init__()。
可以看出,需要严格考虑得设计原则本来就要少得多,依赖倒转和最少知道两条足矣。
但是对于Java这样的静态语言来说,单例模式是常用的一个创建型模式.
二、目标
保证一个类仅有一个实例,并提供一个访问它的全局访问点。
三、适用情景
全局仅需要一个实例,即该实例为无状态的纯功能组件或者全局需要共享状态的组件.
例如设备管理器、唯一序列号生产器就应该使用单例模式,否则很难达到管理和唯一的目的.
也许你会疑惑一个问题:如果是无状态的纯功能组件,为什么不设计把所有方法和成员变量都设计为静态(static)的呢?
的确,从某种意义上讲,类其实就是天然的单例模式,因为Class对象是只能有一个的.
但是某些时候,没法使用类,因为静态方法是属于Class对象的,不管是什么权限的,都无法被继承和实现.
而面向接口编程的原则,意味着很多时候你需要去实现接口,提供接口定义的方法,而静态方法没法做到这点.
四、实现方式
1.私有化构造器
首先我们需要思考的问题是,如何保证一个类仅有一个实例.
为了这个目标,我们首先需要确认的是语言中有哪些实例化的方式,其中哪些实例化方式是能被该类外部调用的,然后将这些方式禁止掉,才能达到目标.
在Java中,实例化一个对象的方式有构造器(constructor)、克隆(clone)、反序列化(deserialization)三种.
也许你会认为还可以使用反射(reflect)来是实例化一个对象.
但是实际上反射最后调用的还是构造器函数.
对于克隆,单例模式类是永远不应该有这样的需求的,所以根本不应该实现Cloneable接口,无需考虑如何禁止.
反序列化,通常需要使用单例模式的类是没有这种需求的,也不会去实现Serializable接口,所以一般也不需要特意去禁止.
如果你的单例类有序列化需求的话,请参考《Effective Java》第3条用私有的构造器或者枚举类型强化Singleton属性:
为了使利用这其中一种方法实现的Singleton类变成是可序列化的( Serializable )(见第11 章),仅仅在声明中加上“ implements Serializable ”是不够的。为了维护并保证Singleton, 必须声明所有实例域都是瞬时( transient )的,并提供一个 readResolve 方法(见第77 条)。否则,每次反序列化一个序列化的实例时,都会创建一个新的实例,比如说,在我们 的例子中,会导致“假冒的Elvis”。为了防止这种情况,要在 Elvis 类中加入下面这 个 readResolve 方法:
// readResolve method to preserve sigleton property private Object readResolve() { // Return the one true Elvis and let the garbage collector // take care of the Elvis impersonator. return INSTANCE; }
而对于禁止构造器被别的类使用,也非常简单,只要对Java的语法稍有了解的人就能写出如下的代码完成该要求.
public class Singleton {
private Singleton(){}
}
如上面的示范代码一样,只需要将构造器函数的权限设置为私有(private)行了.
实际上,这不能百分百保证该类的构造器不被其他地方的代码调用,因为Java中存在着反射机制这样的黑魔法.使用反射完全能够将私有的构造器函数设置为可访问的,并且使用该构造器.
如果需要抵御这种攻击,可以修改构造器,使用如下下发,让它在被要求创建第二个实例的时候创建异常。
public class Singleton {
private Singleton(){
if (instance!=null){//判断静态单例变量是否为null,即是否为第二次调用构造函数.
throw AssertionError();
}
}
}
2.非延迟加载单例(饿汉式)
(一)写法
然后我们要做的就是在单例类中实例化对象并且提供一个外部访问入口.
既然禁止了外部实例化,那么访问入口自然只能是静态的.
所以只需要稍微再加一行代码,单例模式就完成了.
以下代码为写法一:
public class Singleton {
public static final Singleton instance = new Singleton();
private Singleton (){}
}
是的,实际上只需要两行代码,最普通的单例模式就完成了.
也许你会说,你写的这个饿汉式单例和其他文章写的怎么不一样.
确实,其他单例模式的文章写的都是类似如下的代码,以下代码为写法二::
public class Singleton {
private static final Singleton instance = new Singleton();
public static Singleton getInstance() {
return instance;
}
private Singleton (){}
}
事实上,两者的不同仅仅在于给变量封装了工厂方法而已.
《Effective Java》第3条:用私有的构造器或者枚举类型强化Singleton属性中说明了工厂方法的好处:
工厂方法的优势之一在于它提供了灵活性:在不改变其API的前提下,我们可以改变该类是 否应该为Singleton的想法。工厂方法返回该类的唯一实例,但是,它可以很容易被修改,比如改成为每个调用该方法的线程返回一个唯一的实例。
如果你的JDK版本超过1.5的话,还有更优雅简洁的写法三,可以称之为枚举(enum)单例:
public enum Singleton{
INSTANCE;
}
枚举单例不但写法简洁,而且无偿地提供了序列化机制,绝对防止多次实例化,即使在面对复杂的序列化或者反射攻击的时候.
在绝大部分情况下,这种写法的单例模式就已经够用了.
这种单例模式,不但在单线程环境安全,多线程环境也同样保证安全.因为非延迟加载单例实际是类对象实例化时初始化的,而为了保证类对象的单例性,Java保证了类对象的加载过程是单线程的.
(二)缺点
(1)类加载时就会实例化,在少数情况下造成浪费
网上某些文章会说这种写法会导致程序启动就实例化这个单例类,但是可能最后都没有用过这个实例,属于非常浪费内存的写法.
实际上,这根本不正确,这样说的人可以说是根本不了解Java的相关规范.Java并不会在JVM启动时就将所有类对象加载并初始化.
类的初始化,包括生成对象的初始化和类的静态块的实例化。
初始化触发的时机: 类被直接引用(主动引用)的时候。
主动引用的情形有:
使用new关健字实例化对象
使用类的静态变量
使用类的静态方法
当初始化一个类时,发现其父类还未初始化,则先触发父类的初始化
使用反射机制调用上述操作
虚拟机启动时,定义了main()方法的那个类先初始化
对于一个单例类,new实例化只能在自己类中,所以排除第1条.同时构造器私有权限也意味着不可能有子类,也排除第4条.也不可能是main方法入口,所以也排除第6条.
所以实际上只有当单例类的有除了提供全局访问点以外的非私有(not-private)的静态变量或者静态方法会在实例化以前被人调用时(反射调用也包括)才会产生实例化对象却没有被使用的浪费内存的现象.
而且即使产生了浪费,一个单例类对象浪费的内存大部分时候根本不需要在乎.
当然,某些时候,创建一个单例类需要耗费的资源较多,这种浪费有避免的需要.
(2)依赖参数配置实例化时无法适用
如果该实例的创建是依赖参数或者配置文件的,在 getInstance() 之前必须调用某个方法设置参数给它,那样这种单例写法就无法使用了.
3.线程不安全延迟加载单例(懒汉式)
如果遇到了上面所说的罕见情况,或者说出于程序员追求完美的强迫症,要避免浪费,那么我们就需要做到延迟加载(lazy load).如果遇到了上面所说的罕见情况,或者说出于程序员追求完美的强迫症,要避免浪费,那么我们就需要做到延迟加载(lazy load).
(一)写法
也许你会认为这还不简单?然后随手写下下面的代码:
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static Singleton getInstance() {
if (instance == null) { //#1
instance = new Singleton();
}
return instance;
}
}
(二)缺点
然而只要对多线程稍有理解的程序员就立刻能看出问题:假如多个线程同时进入了#1这行代码,那么就会实例化多个对象.
所以说这样的代码,只能在单线程情况下保证安全.如果是多线程情况下,就无法保证”单例”的目的.
事实上,真正生产上使用的代码,基本上都是多线程环境的.因此大多数情况下,这个写法是不能使用的.
4.同步延迟加载单例
(一)写法
也许你又会说这也好解决,保证同步不就行了嘛.在Java里只要加上synchronized关键字就能使方法变成同步方法了:
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
或者是这样
public class Singleton {
private static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
return singleton;
}
}
(二)缺点
这样的代码的确达到了多线程情况下保证单例的目的,但是实际上这造成了不少性能上的浪费.
因为这样的synchronized关键字是直接使整个方法变成了同步方法,每次获取实例都需要同步.
但是实际上稍微一思考就能发现,我们只需要第一次实例化时同步就够了,后面的同步全都是不必要的.
通常情况下,需要在多线程环境下使用延迟加载的单例类,被调用获取实例的方法都是很频繁的,否则也没有必要考虑多线程下的重复实例化问题了.
如果是出于程序员的完美追求,那更是不能容忍这种情况了.
5.双重检测(double checked)延迟加载单例
也许你稍加思考,立刻对上面的代码做了改进:
public class Singleton {
private static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
然而这又是一种错误的写法.这种写法的错误之处必须从JVM的内存模型以及synchronized关键字的语义说起.
(一)指令重排序
指令重排序的概念和原因其实非常简单.
为了尽可能地提升运算效率,利用好各层的缓存,JVM的内存模型允许将代码所编译出的机器指令重新进行排序,而不是一定要保持原有顺序.
public class Test{
public static void main(String[] args) {
int x=10;//#1
int y=8;//#2
}
}
以上面的代码为例,尽管代码上表示应该先执行#1,再执行#2,但是实际上在机器指令执行的顺序并不一定如此,可能是先执行#2再执行#1.
我想你肯定会疑惑,如果这样做的话,那怎么保证结果正确呢?毕竟很多时候,交换了执行顺序,结果就会不一样.
(二)先行发生(Happens Before)规则
为了保证指令重排序后,程序运行结果的正确,于是引入了先行发生规则.
先行发生规则是规定和描述各个操作之间可见性的规则.
如果操作A先行发生于操作B,那么A操作的一切结果都对B操作是可见的.
注意,先行发生和时间上的先后是两个概念,两者互不包含.先行发生关系保证一定能够观测到前一个操作施加的内存影响,只有时间上的先后关系而并没有先行发生关系可能但并不保证能观测前一个操作施加的内存影响.
Java规定了如下几条先行发生规则,以下内容摘自《深入理解Java虚拟机》第12章:
(1)程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
(2)锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作;
(3)volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;
(4)传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C;
(5)线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作;
(6)线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
(7)线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
(8)对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始;
在单线程情况下,对于先行发生规则只需要看第(1)条即可.
这条规则是说,在单线程 中操作间happen-before关系完全是由源代码的顺序决定的,这里的前提“在同一个线程中”是很重要的,这条规则也称为单线程规则 。
修改一下上面的代码:
public class Test{
public static void main(String[] args) {
int x=10;//#1
int y=x+1;//#2
}
}
运用先行发生规则(1)进行分析,此时#1和#2绝对不会发生指令重排序.
因为#1和#2在同一线程中,所以#1happen-before#2,所以#1的操作结果必须对于#2的操作可见.
而正好#2中又读取了#1的操作结果,所以为了遵守happen-before规则,此时会禁止指令重排序.
(三)可见性
要正确运用happen-before规则分析多线程环境下的可见性问题,首先要理解JVM的内存模式.
JVM的内存模型与操作系统类似,如下图所示:
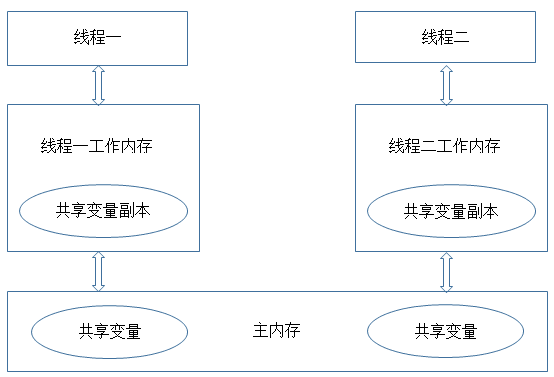
每个线程都有一个自己的工作内存(相当于CPU高级缓冲区,这么做的目的还是在于进一步缩小存储系统与CPU之间速度的差异,提高性能).
对于共享变量,线程每次读取的是工作内存中共享变量的副本,写入的时候也直接修改工作内存中副本的值,然后在某个时间点上再将工作内存与主内存中的值进行同步。这样导致的问题是,如果线程1对某个变量进行了修改,线程2却有可能看不到线程1对共享变量所做的修改。
这就是多线程环境下,时间先后关系无法保证happen-before关系想要保证的可见性的原因.
(四)synchronized
Java中synchronized的语义有(1)确保线程互斥的访问同步代码(2)保证共享变量的修改能够及时可见(3)一定程度的禁止重排序
happen-before规则第(2)条中的锁就与synchronized关键字有关,synchronized就是一种锁.
事实上,这几点之间是互相关联的.
确保线程互斥的访问同步代码就是让代码块中的执行环境变成了单线程,此时happen-before规则第(1)条就起作用,一定程度地禁止了同步块内部代码指令重排序,以及禁止了同步块内代码与同步块外代码的指令重排序.
保证共享变量的修改能够及时可见与happen-before规则第(2)条的规定本质相同.
所以JMM对于synchronized规定如下:
- 线程解锁前,必须把共享变量的最新值刷新到主内存中.
- 线程加锁时,必须清空工作内存中共享变量的值,从而使用共享变量是需要从主内存中重新读取最新的值.
(五)错误原因
接下来我们运用上面说到的概念和知识来分析前面的双重检查的代码错误所在.如果有下面的代码:
public class Singleton {
private static Singleton singleton;
private int field;
private Singleton (){
field=9;// #1
}
public int getField(){
return field;//#2
}
public static Singleton getSingleton() {
if (singleton == null) {//#3
synchronized (Singleton.class) {//#4
if (singleton == null) {//#5
singleton = new Singleton();//#6
}
}
}
return singleton;//#7
}
}
分析多线程情况下其中的happen-before关系,存在happen-before关系的只有第一个进入同步块的线程的#5和#6,以及先进入同步块的线程对后进入同步块线程的happen-before关系.
singleton = new Singleton()这样的初始化一个实例的代码会有4个步骤.
(1)申请内存空间,
(2)初始化默认值(区别于构造器方法的初始化),
(3)执行构造器方法
(4)连接引用和实例
这4个步骤都在synchronized块中,因此指令重排序是完全被允许的,所以(3)(4)的执行顺序有可能是(4)(3).
当执行顺序为(4)(3)时,如果进行实例化的线程A进行到(4)时,让出计算时间,线程B调用了getSingleton().getField()的代码时,由于不存在happen-before关系,线程B可能在#3看到未完成实例化,但是已经不是null的对象.
此时线程B获得的field值有可能是默认值0而不是9,这是理论上不该发生的情况.
这种单例对象未完成实例化就被获取使用的情况,就是这种写法的错误所在.
(六)写法
实际上只需要增加一个关键字volatile就能修正上面写法的bug.
public class Singleton {
private static volatile Singleton singleton;
private int field;
private Singleton (){
field=9;// #1
}
public int getField(){
return field;//#2
}
public static Singleton getSingleton() {
if (singleton == null) {//#3
synchronized (Singleton.class) {//#4
if (singleton == null) {//#5
singleton = new Singleton();//#6
}
}
}
return singleton;//#7
}
}
此时,以->符号记happen-before关系.
线程A#6->线程B#3;
线程A#1->线程A#6
线程B#3->线程B#7->线程B#2
因此,根据传递性,可得出线程A#1->线程A#6->线程B#3->线程B#7->线程B#2.
所以线程A#1一定happen-before线程B#2,因此线程A#1的写入必须被线程B#2可见.
如果对使用happen-before关系分析觉得很乱的话,也可以从volatile关键字在Java内存模型(JMM)中的禁止指令重排序规则来理解.
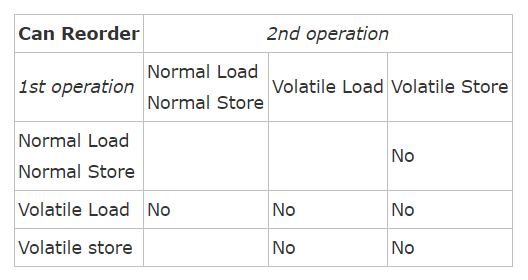
由于singleton变量的赋值为volatile store操作,由图可知,当第二个操作是volatile store操作时,无论前面的第一个操作是什么,都不允许指令重排序,保证了先执行构造函数,再赋值的顺序,自然也就修复了上面代码的bug.
(七)缺点
(3)volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;
以上volatile变量的happen-before规则是在Java1.5加入的.
所以JDK1.5以前不适用.
6.静态内部类延迟加载单例
事实上,使用双重检查锁定已经是走入了更复杂的道路.事实上,非延迟加载单例中的以类对象加载单例保证的思路,完全可以使代码更简洁.
public class Singleton {
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
private Singleton (){}
public static final Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}
原理依旧是类对象的实例化为单线程.
这样的写法既简单,又容易理解,而且不存在JDK的版本要求.
五、总结
除了确定必须要设计单例类需要根据配置参数进行延迟实例化的情况,应该都只使用枚举类单例或者出于语义规范使用非延迟加载单例.
如果必须根据配置参数进行延迟实例化,那么应当使用静态内部类单例.
参考列表
《Effective Java》中文版 第2版 Joshua Bloch(美)